在軟體工程中,我們常會面臨服務 high latency 的問題,而要解決這個問題,理解 throughput 與 latency 的關係是關鍵。
名詞定義
什麼是 throughput 與 latency?
- latency:處理一個請求需要花多少時間。從請求進來到回應出去的時間差。通常用毫秒 (ms) 來量測。越低越好。
- throughput:單位時間內能處理多少請求。通常用 RPS (Requests Per Second) 或 QPS (Queries Per Second) 來表示。越高越好。
server 如何工作
server 接收請求後,由一個或多執行緒(threads)處理請求並生成回應。單執行緒 server 一次只能處理一個請求,而多執行緒 server 可以同時處理多個請求。
想像一下你的伺服器就是一家自助洗衣店。請求就像是帶衣服來洗的客人。
單執行緒的伺服器就像店裡只有一台洗衣機,一次只能服務一個客人。客人得排隊。 多執行緒/多進程/異步 I/O 的伺服器就像有多台洗衣機,可以同時服務多個客人。
- latency:從顧客開始操作洗衣機到洗衣完成的時間。這包括顧客等候空閒洗衣機的時間,以及實際洗衣的時間。等候時間越長,latency 越高。
- throughput:洗衣店每小時完成的洗衣次數。洗衣機數量越多,洗衣店能處理的顧客數量越多,throughput 越高。
latency 與 throughput 的關係
很多人以為 latency 和 throughput 的關係是簡單的線性反比,或者覺得加機器就能解決一切。但現實更殘酷一點。
起初,當客人不多(請求量低)的時候,洗衣機(伺服器資源)很空閒,客人一來就能馬上洗,這時候 latency 很低,主要就是洗衣機本身運作的時間(我們稱之為 service time 或 true latency)。
隨著客人變多(請求量增加),洗衣機開始被佔滿。當所有洗衣機都在運作時,新來的客人就得排隊等了。這段等待時間就是 queueing latency。
Total Latency = Queuing Latency + Service Time
這時候,你會看到,throughput 接近洗衣店的極限(例如,4台洗衣機,每台半小時,極限就是 8 籃/小時),但 latency 開始飆升。因為客人等的時間越來越長。這不是線性增加,通常是指數級的暴增,形成一個像曲棍球棒(hockey stick)的曲線。一旦系統利用率(utilization)超過某個閾值(比如 70-80%),一點點 throughput 的增加都可能導致 latency 急劇惡化。
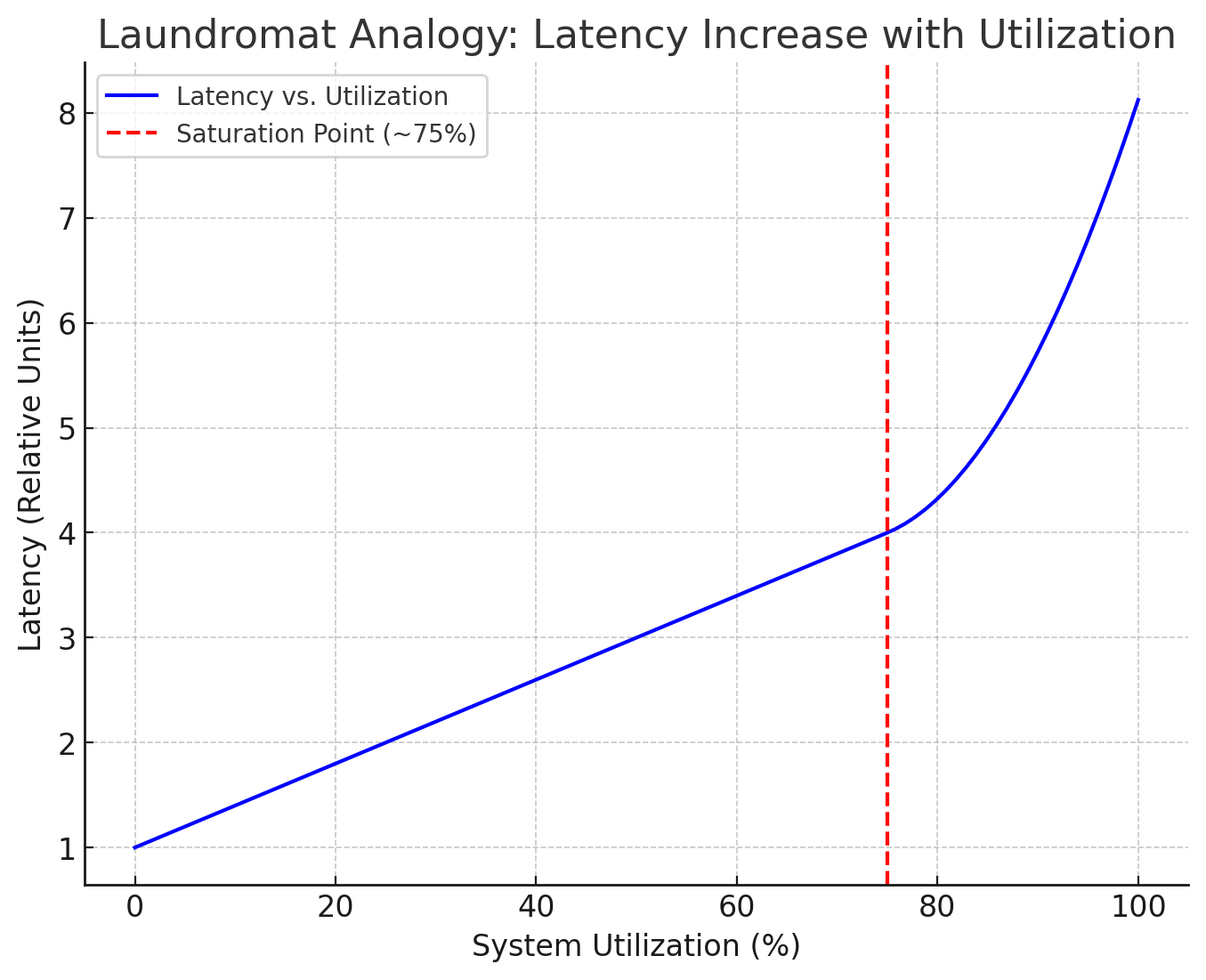
這背後的原因是資源競爭。CPU、記憶體、網路頻寬、資料庫連接池、甚至是你程式裡的鎖(lock),任何有限的資源都可能成為瓶頸,導致排隊。
有個叫做 Little’s Law 的排隊理論公式:L = λW
- L:系統中平均的請求數(排隊的 + 正在處理的)
- λ:請求到達的平均速率(也就是 throughput)
- W:一個請求在系統中平均停留的時間(也就是 latency)
這告訴我們,當 throughput (λ) 增加時,如果 latency (W) 不變(理想情況),系統中的請求數 (L) 會增加。但當系統接近飽和,latency (W) 會因為排隊而增加,這會進一步推高系統中的請求數 (L),形成惡性循環。
實際案例分析
以下是兩個實際案例,說明如何應用這些概念來解決高 latency 問題:
案例一:電商網站的促銷活動
Scenario: 在一個電商網站中,某次促銷活動期間,網站的 latency 突然大幅增加。經過分析,發現網站的請求數量超過了 server 的處理能力,導致大量請求被排隊等待,造成高 latency。
原分析:增加執行緒、優化 DB 查詢。
深入分析:監控發現 P99 latency 飆高,DB 連接池滿載 (queueing)。Profiling 顯示某個計算折扣的函數因為涉及多次 DB 查詢而變慢 (service time)。 解法:
- 增加 DB 連接池大小 (提升 throughput)。
- 將折扣計算涉及的部分商品資訊快取到 Redis (降低 service time)。
- 將訂單成功後的通知 email 改為非同步發送 (降低 perceived latency, 提高 request thread throughput)。
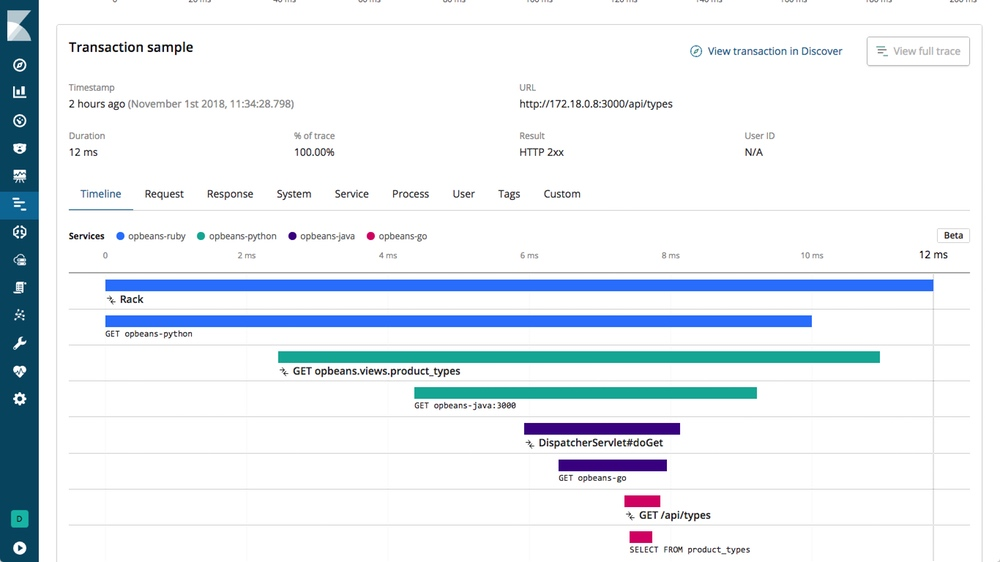
案例二:SATA 與 NVMe 類型的 SSD
Scenario: 考慮要用哪種 Storage
深入分析:儲存裝置的效能是影響 Service Time Latency 和系統整體 Throughput 的關鍵因素。不同的儲存技術在處理 I/O 請求時,速度和並行處理能力差異很大,直接影響應用程式的回應速度,尤其是在高負載情況下。
比較一下常見的儲存類型:
| 特性 | 7200rpm HDD (傳統硬碟) | SATA SSD (固態硬碟) | NVMe SSD (固態硬碟) |
|---|---|---|---|
| 連接介面 | SATA | SATA | PCIe (直接連接 CPU) |
| IOPS (約略值) | 數百 | 數萬 | 數十萬 至 數百萬+ |
| Bandwidth (約略值) | 100-200 MB/s | 500-600 MB/s | 2,000 - 7,000+ MB/s |
| Latency (約略值) | 毫秒 (ms) 等級 | 微秒 (µs) 等級 (較高) | 微秒 (µs) 等級 (極低) |
| 並行處理能力 | 差 (機械尋道限制) | 好 (AHCI 限制) | 極佳 (NVMe 協議優化) |
| 適合場景 | 大容量儲存、冷資料、備份 | 一般使用者、系統碟、輕負載 | 高效能運算、資料庫、高負載 |
| 對 Latency 影響 | 高負載時 Queueing 嚴重 | 高負載時 Queueing 明顯 | 高負載時 Queueing 顯著減少 |
說明:
- IOPS (Input/Output Operations Per Second):每秒可處理的讀寫次數,代表處理大量小檔案或隨機存取的能力。IOPS 越高,處理並行請求的能力越強,能有效降低 Queueing Latency。
- Bandwidth (頻寬):每秒可傳輸的資料量,代表處理大檔案或循序存取的速度。頻寬越高,讀寫大檔案越快。
- Latency (延遲):完成一次讀寫操作所需的時間。延遲越低,單次操作越快,直接影響 Service Time Latency。
- 並行處理能力:NVMe 使用 PCIe 介面,相比 SATA 介面頻寬更高、延遲更低。更重要的是,NVMe 協議本身就是為固態硬碟和並行處理設計的,支援更深的命令隊列 (Command Queuing) 和更有效的多核心 CPU 利用,能夠同時處理更多 I/O 請求,大幅減少作業系統層面的排隊等待 (Queueing Latency),CPU 的開銷 (overhead) 也更低。SATA SSD 雖然比 HDD 快很多,但仍受限於 SATA 介面和 AHCI 協議,在高並行負載下瓶頸較明顯。
除了單一硬碟的效能,我們還可以透過組合多個硬碟來進一步提升效能和可靠性,常見的方法有 RAID 和 ZFS:
| 技術/配置 | 類型 | 主要優點 | 主要缺點 | 效能影響 (大致) | CPU 負載 (軟體) |
|---|---|---|---|---|---|
| RAID 0 | Stripe | 最高讀寫 Throughput/IOPS | 無冗餘,單碟壞=全滅 | 讀/寫 ≈ N * 單碟 | 低 |
| RAID 1 | Mirror | 高讀取 Throughput/IOPS、高冗餘 | 寫入效能 ≈ 單碟、容量減半 | 讀 ≈ N * 單碟, 寫 ≈ 單碟 | 低 |
| RAID 5 | Parity | 容量效率高、讀取效能好、冗餘 | 寫入效能較差 (寫入懲罰)、重建慢 | 讀 ≈ (N-1)*單碟, 寫 < 讀 | 中 |
| RAID 6 | Double Parity | 比 RAID 5 更高冗餘 | 寫入效能更差、容量效率稍低 | 讀 ≈ (N-2)*單碟, 寫 < RAID 5 | 中高 |
| ZFS Stripe | Stripe | 同 RAID 0 | 同 RAID 0 | 同 RAID 0 | 中 |
| ZFS Mirror | Mirror | 同 RAID 1 + ZFS 功能 (checksum 等) | 同 RAID 1 | 同 RAID 1 | 中 |
| ZFS RAID-Z1/2/3 | Parity | 同 RAID 5/6 + ZFS 功能 | 同 RAID 5/6 (寫入懲罰稍不同) | 類似 RAID 5/6 | 高 |
說明:
- N 代表陣列中的硬碟數量。
- RAID (Redundant Array of Independent Disks):傳統的硬碟陣列技術,可由硬體 RAID 卡或作業系統軟體 (如 Linux 的 mdadm) 實現。硬體 RAID 卡通常不消耗主機 CPU 資源,但有自己的處理器和快取,可能成為瓶頸且價格較高;軟體 RAID 會消耗主機 CPU 資源。
- ZFS:更現代的檔案系統和邏輯卷管理器,提供資料完整性校驗、快照、壓縮等高級功能,其 RAID-Z 是在軟體層面實現,會消耗 CPU 和記憶體資源,但通常比傳統軟體 RAID 更靈活和可靠。
- 效能影響是粗略估計,實際表現受控制器、快取、工作負載等影響。
- 使用 RAID 或 ZFS 可以透過聚合多個硬碟的 IOPS 和頻寬來顯著提升系統的 Throughput,進而降低在高負載下的 Queuing Latency。但選擇哪種配置需要在效能、容量、可靠性和成本之間做權衡。
案例三:微服務 API Gateway 延遲高
Scenario:一個 API Gateway 需要呼叫三個後端微服務 (User, Product, Order) 來組合回應。 問題:監控顯示 Gateway 的 P95 latency 高達 500ms。 分析:Tracing (用 Jaeger 或 Zipkin) 發現請求是串行的:Gateway -> User (50ms), Gateway -> Product (100ms), Gateway -> Order (150ms),加上 Gateway 自身的處理和網路延遲,總時間很容易疊加。 解法:
- 並行請求:Gateway 同時發送請求給三個後端服務,總時間取決於最慢的那個 (150ms) + Gateway 處理時間 + 網路延遲。可以用 Go 的 goroutine + WaitGroup 或
errgroup輕鬆實現。 - 快取:如果 User 或 Product 資訊不常變,可以在 Gateway 層快取它們的結果,避免每次都去呼叫。
- HTTP/2 或 gRPC:如果後端服務之間是用 HTTP/1.1,可能會遇到 Head-of-Line Blocking。升級到 HTTP/2 或 gRPC 可以利用多路復用 (multiplexing) 改善並行請求的效率。
如何解決高延遲問題?
搞清楚 latency 飆高的原因是排隊(queuing)還是服務本身變慢(service time)非常重要。
-
檢查監控指標:
- P95/P99 Latency:看這個比看平均 latency 有用。平均值很容易被少量極快或極慢的請求誤導。如果 P99 latency 飆高,但 P50 (中位數) 還好,通常代表有長尾請求或偶發性的排隊。
- Throughput (RPS/QPS):請求量是否真的增加了?有沒有超過系統設計的容量?
- 資源利用率 (Utilization):CPU、記憶體、磁碟 I/O、網路頻寬是不是被打滿了?
- Queue Depth/Length:如果你的應用程式或依賴的服務(如資料庫、消息隊列)能看到隊列長度,這是判斷排隊延遲最直接的指標。
- 錯誤率:高延遲常常伴隨著錯誤率上升。
-
找出瓶頸:
- 如果是 Queuing Latency 增加 (高利用率、長隊列、throughput 接近極限但 latency 狂飆):
* 解法:提升 Throughput 能力。
- 垂直擴展 (Scale Up):換更強的機器 (更多 CPU、RAM)。
- 水平擴展 (Scale Out):加更多機器實例,用 load balancer 分流。這是最常見的解法。
- 優化資源使用:看看是不是有不必要的資源浪費。
- 如果是 Service Time 增加 (利用率不高,但 latency 就是變慢了,甚至 throughput 下降):
* 解法:降低單一請求的 Latency。
- 程式碼優化:用 profiler (例如 Go 的 pprof) 找出慢的函數、演算法。是不是有 N+1 查詢?是不是有不必要的計算或 I/O?
- 資料庫優化:慢查詢?沒加索引?資料庫鎖競爭?連接池不夠用?
- 外部依賴:是不是呼叫的第三方 API 變慢了?網路抖動?
- 快取 (Caching):在合適的地方加快取 (記憶體快取、Redis/Memcached、CDN) 是降低 latency 的大殺器。但要注意快取失效、一致性問題。
- 非同步處理 (Async):對於不需要立即回傳結果的操作(例如發送 email、記錄 log),把它們丟到背景隊列處理,讓請求執行緒趕快釋放出來處理下一個請求。這能有效提高 throughput 並降低 perceived latency。
- 架構調整:有時候是架構本身的問題。例如,單體應用裡某個模組拖慢了整體;或是微服務之間呼叫鏈太長,網路延遲疊加。考慮事件驅動、CQRS 等模式。
Latency 和 Throughput 是系統效能的一體兩面。解決高延遲問題,不能頭痛醫頭、腳痛醫腳。你得先用監控和分析工具搞清楚瓶頸在哪,判斷是排隊問題(需要提高 throughput 容量)還是處理本身慢(需要降低 service time latency),然後才能對症下藥,透過擴展、優化程式碼、加快取、非同步化或調整架構來解決。記住 P99 latency 和 queue depth 這些指標,它們通常更能反映真實的用戶體驗和系統瓶頸。